– DOI: 10.1016/j.cell.2024.05.039
Pan-cancer proteogenomics expands the landscape of therapeutic targets
留意最新动态,请关注微信公众号:组学之心
最近课题组在写泛癌的综述,刚好这篇相关研究论文在6.24发表,新鲜出炉,来欣赏一下。文章解读过程中带有个人的观点,如有理解错误,劳请指正。(听劝系列)
研究团队和单位
Baylor College of Medicine–章冰

复旦大学生物医学研究院–高强

:::
::::
文章简介
- 研究背景和数据来源:
蛋白质是分子靶向疗法的主要靶点,但是现有FDA批准的抗癌药物靶向的蛋白质不到 200 种。研究整合了临床蛋白质组肿瘤分析联盟(CPTAC)提供的来自10种癌症类型、1,043 名患者的蛋白质基因组学数据,与其他公共数据集结合,以确定潜在的治疗靶点。
- 主要研究发现:
1.研究对 2,863 种可用药蛋白质的全癌分析揭示了广泛的丰度范围,确定了影响mRNA-蛋白质相关性的生物学因素,蛋白质丰度并非完全由mRNA水平决定,而是受到多层次调控的结果。
2.通过整合来自肿瘤的蛋白质组学数据和来自细胞系的遗传筛选数据,识别了蛋白质过表达或过度活化驱动的可用药依赖性,从而能够准确预测有效的药物靶点。
3.蛋白质组学发现合成致死性有助于靶向肿瘤抑制因子的丧失。
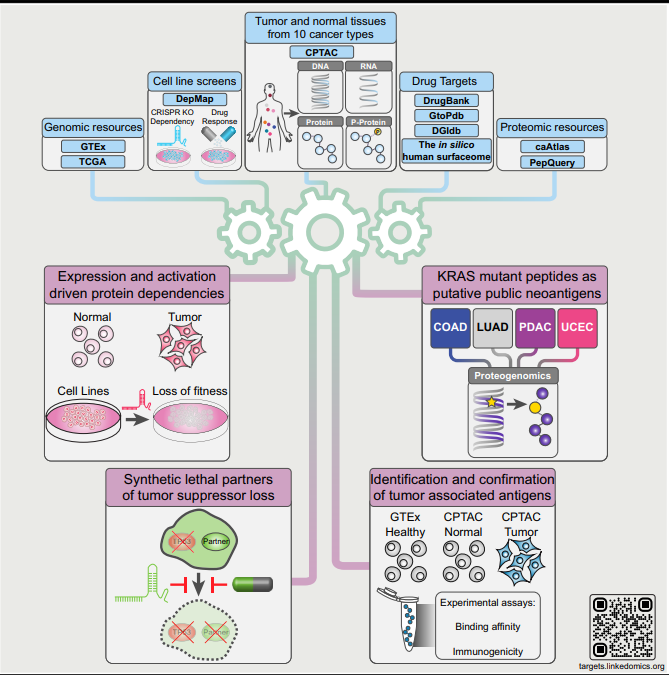
4.新抗原预测:联合蛋白质基因组学分析和MHC结合预测分析,将突变型KRA肽优先列为影响最大的抗原。通过计算鉴定肿瘤中共有的肿瘤相关抗原,在实验确认后,可将肽作为免疫治疗靶点。这些分析存放在在https://targets.linkedomics.org上,公开作为伴随诊断、药物再利用和开发治疗性蛋白质和肽靶标的综合型工具。
研究结果
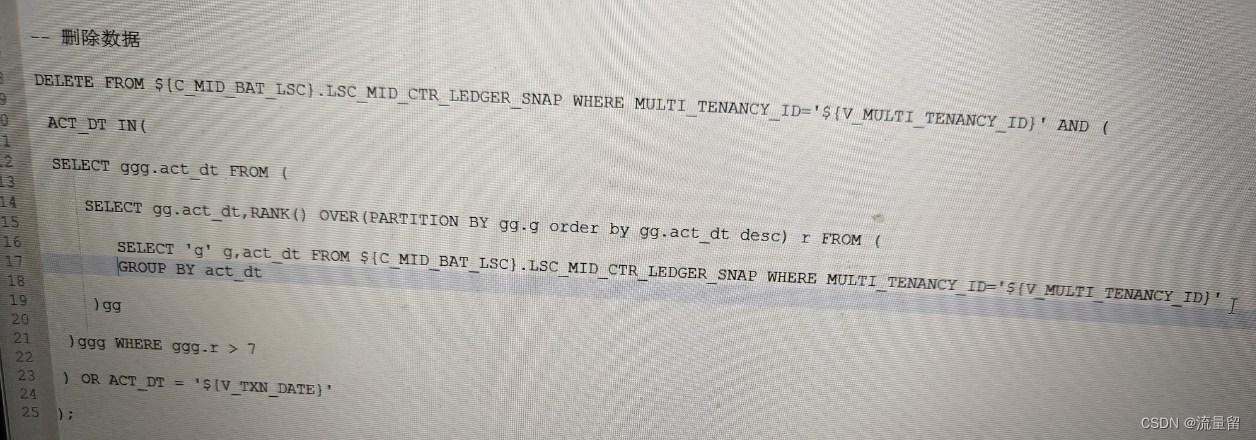
1.对可作为药物靶点的基因进行蛋白质组学定量分析
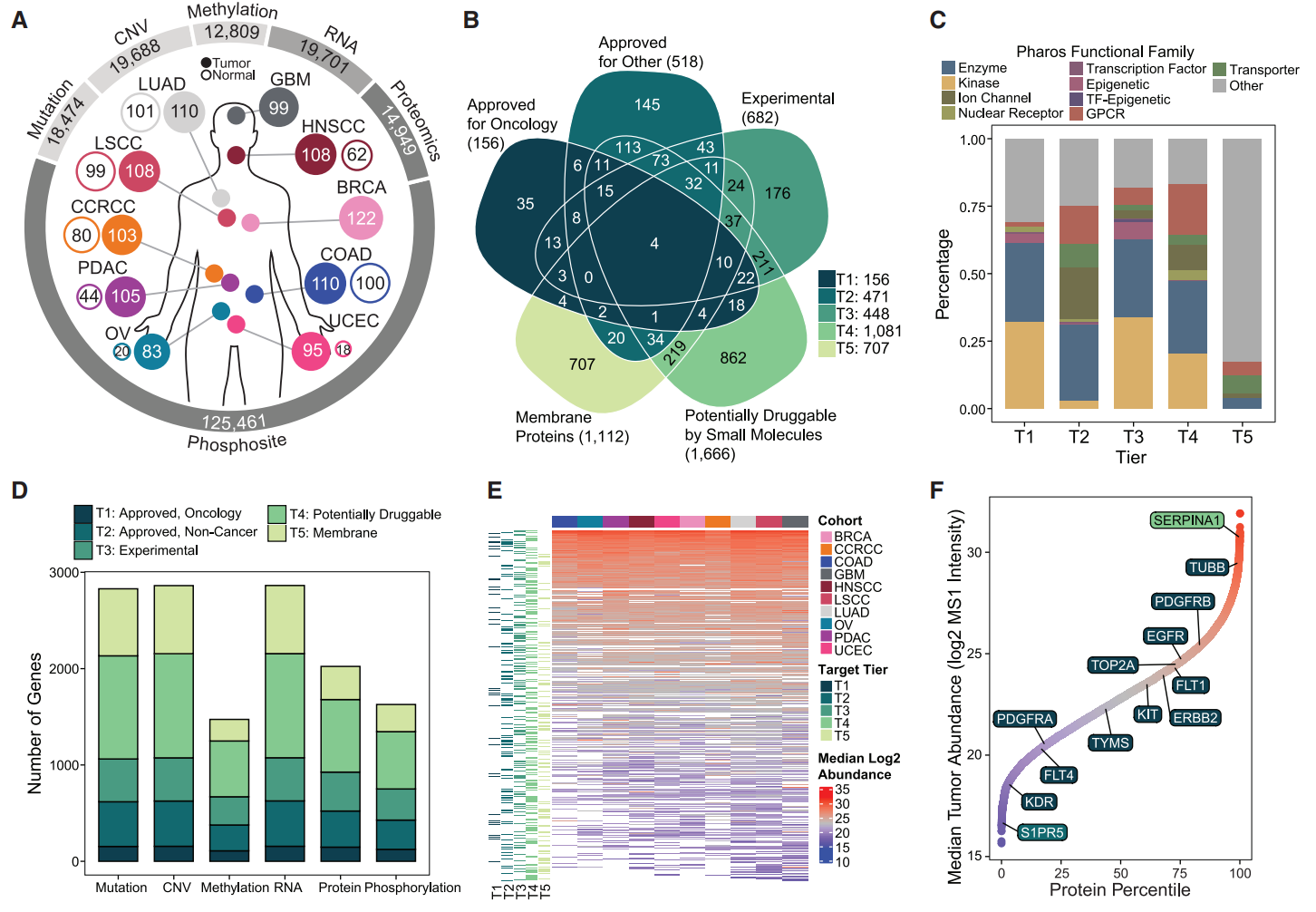
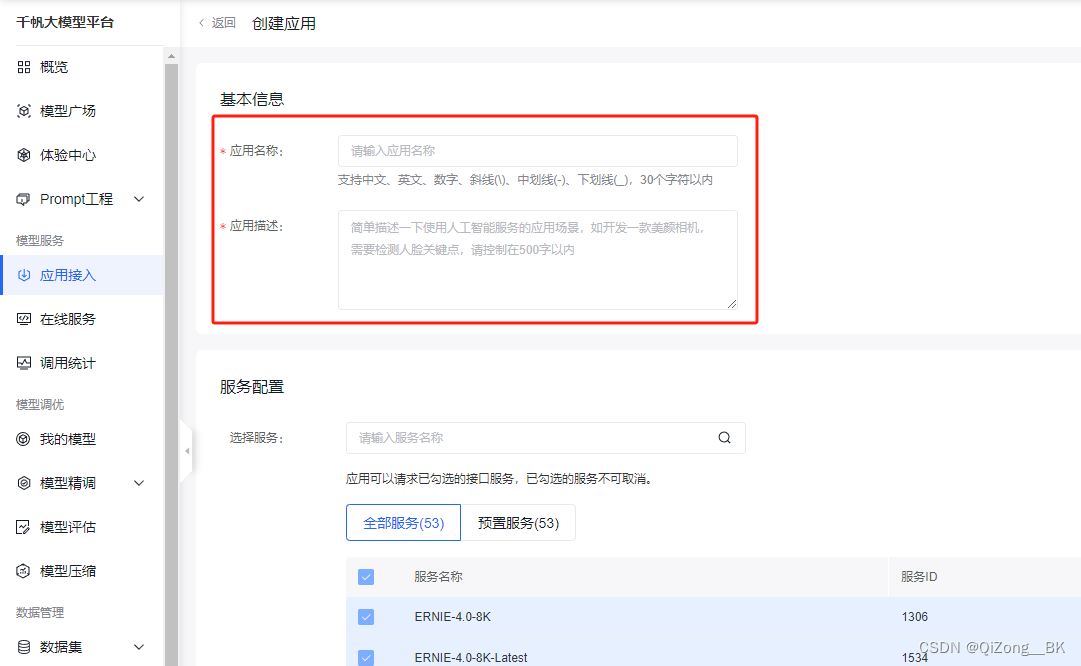
(A)研究分析了10种癌症类型的1,043个肿瘤样本和524个正常组织样本的CPTAC蛋白质组学数据。涉及突变、拷贝数变异 (CNV)、甲基化以及转录、蛋白质和磷酸位点丰度数据分析。
(B-C)研究从DrugBank、GtoPdb、药物基因相互作用数据库和计算机模拟人类表面组收集了药物靶标信息,并将靶标分为五种类型。1类型是任何监管机构批准用于任何癌症类型的药物的主要抑制靶标,超过30%是激酶。2类是包括批准用于任何其他适应症的药物的471个主要抑制靶标,与1类相比,离子通道和G蛋白偶联受体(GPCR)的比例更高。3 类包含448个被视为研究性或实验性药物抑制的靶标,包括相对较大比例的表观遗传药物。4类包括小分子经常靶向的蛋白质家族中剩余的1,081个基因。5类包括707种细胞表面膜蛋白。
(D)五个靶标层级共包含2,863个基因,所有基因均通过RNA测序(RNA-seq)数据进行量化,而蛋白质组学数据覆盖了71%。
(E)量化的可用药蛋白质在每个队列中显示出广泛的中位蛋白质含量。可用药蛋白质在不同癌症类型中的丰度差异显著,一些蛋白质在某些癌症类型中表现出较高含量,提示其潜在的治疗靶点价值。
(F)在所有队列中,SERPINA1在可用药蛋白质中具有最高的总体中位丰度,而S1PR5 的中位丰度最低。此外,八种或更多种获批肿瘤药物所针对的蛋白质,包括TUBB、PDGFRB、EGFR、TOP2A、FLT1、ERBB2、KIT、TYMS、PDGFRA、FLT4和KDR,也显示出广泛总体含量。提示SERPINA1是泛癌治疗的重要对象,优先级较高;但是不同癌症之间可用药蛋白质含量差异显著,强调了个体化治疗的必要性。
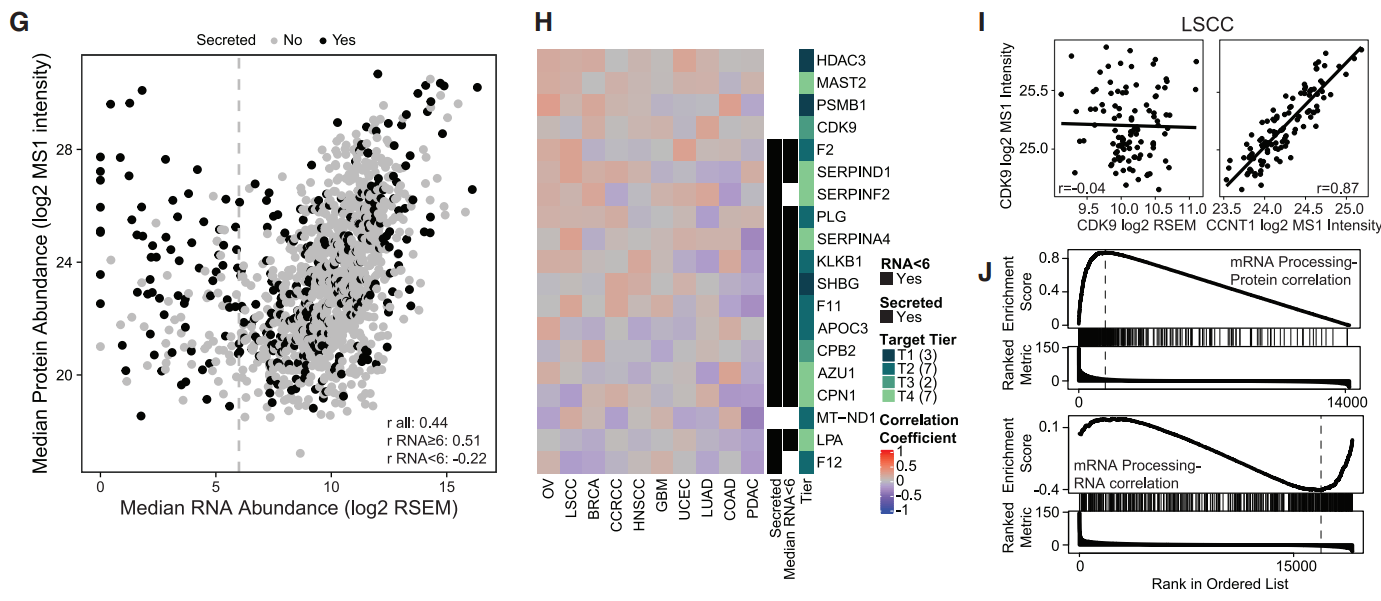
(G)研究观察到人类蛋白质图谱注释的分泌蛋白在mRNA丰度较低的可用药基因中显著富集,表明mRNA水平并不能完全预测蛋白质水平,尤其是在分泌蛋白的情况下,分泌蛋白的这种特性可能是由于其翻译后修饰、分泌机制和蛋白质稳定性等因素导致的。
(H)19个可用药基因在10个肿瘤队列中均未显示出显著的mRNA-蛋白质正相关性,这些基因主要与分泌蛋白相关。其中包括HDAC3和CDK9,这两个基因参与转录调控,但不知道是否分泌。
(I)CDK9蛋白丰度与所有癌症类型的相应mRNA丰度相关性较差,但它与其结合伴侣细胞周期蛋白T1(CCNT1)的蛋白丰度在所有蛋白中表现出最强的关联性,而在 mRNA水平上没有相应的正相关性。
(J)CDK9蛋白共表达的蛋白的基因集富集分析(GSEA)揭示了参与mRNA加工的蛋白显著富集,这是CDK9的已知功能,而与CDK9 mRNA共表达的mRNA则相反。这些结果表明CDK9蛋白水平比其mRNA水平更能代表其功能,强调了直接测量可用药基因的蛋白质丰度是很关键的。
2.蛋白质过表达驱动的可靶向依赖性
标题的意思是:癌细胞依赖过量存在的特定蛋白质生存,我们可以通过设计特定的药物来针对这些蛋白质进行靶向治疗(没办法,文章标题要精炼)
研究比较了肿瘤和正常组织样本,来确定肿瘤中过度表达的蛋白质,并想要筛选出对癌细胞存活和增殖至关重要的蛋白质。

(A)利用从DepMap数据库下载的相应谱系癌细胞系中CRISPR-Cas9筛选实验的基因依赖性评分。在8个正常样本队列中,999–2914个基因在肿瘤组织中均表现出显著过表达,并且细胞系中敲除基因后的细胞生长显著减少,初步筛选出对癌细胞存活和增殖至关重要的蛋白质。
(B)其中,总共457种蛋白质可分为5个类。其中51种蛋白质至少是5种癌症类型共有的,并且未被DepMap指定为pan-必需蛋白质。这些可靶向的泛癌症依赖性包括5个一类靶点、7个二类靶点(提示有药物再利用机会)、19个三类靶点(可能为实验药物提供指征)以及15个四类和5个五类靶点(是新疗法开发的良好候选者)。值得注意的是,一类靶点GART和三类靶点PAK1在所有八种癌症类型中均表现出过表达和依赖性。
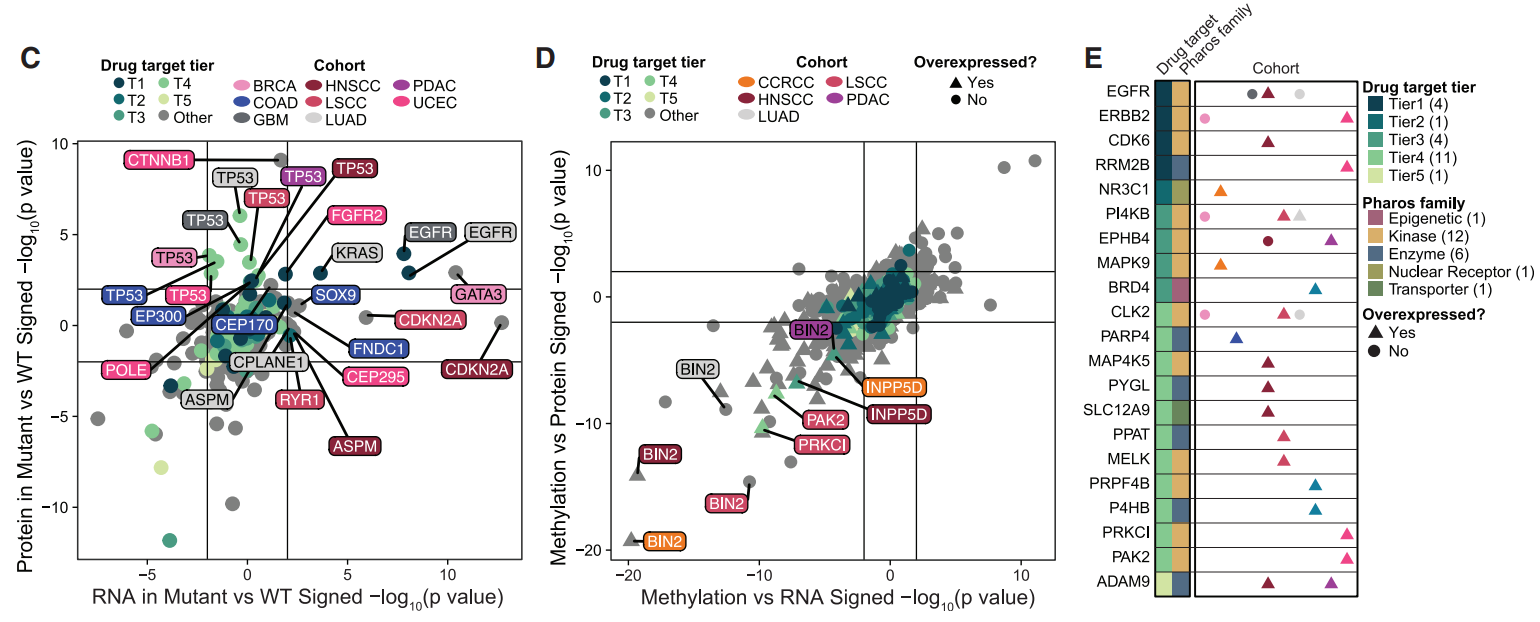
(C)将mRNA和蛋白质表达数据与突变、甲基化和拷贝数数据整合在一起,探究基因/蛋白表达和基因变异之间的关系。在突变分析中,GBM和LUAD中的EGFR突变(经常伴有拷贝数扩增)与EGFR mRNA/蛋白质水平升高有关。GATA3突变会破坏E3泛素连接酶的识别基序,导致BRCA中的蛋白质/mRNA水平升高。CTNNB1突变与UCEC中的蛋白质水平升高有关,但与mRNA水平无关,即CTNNB1中的变异使突变蛋白能够逃避b-Trcp的识别并随后降解。TP53突变,尤其是DNA结合域中的错义突变,与蛋白质丰度升高有关,而它在八个队列中的mRNA并没有相应增加。DNA结合域中的TP53错义突变不仅会破坏蛋白质的DNA结合,还会延长其半衰期。
(D)甲基化相关分析:在LSCC中,激酶PRKCI和PAK2在mRNA和蛋白质水平上显示出甲基化与其表达之间显着负相关性,与正常组织相比,肿瘤中的甲基化水平明显较低,蛋白质丰度较高。同样,BAR衔接子家族蛋白BIN2在五个队列中显示出甲基化与mRNA和蛋白质水平上表达之间显着负相关性。此外,与正常组织相比,在CCRCC,PDAC和HNSCC中发现BIN2在肿瘤中过表达,并且这三种癌症类型的细胞系中表现出依赖性。
(E)拷贝数变异分析:5个类中的44个基因显示出显着更高的mRNA和蛋白质水平以及拷贝数扩增。其中,与正常组织相比,至少1个队列中的21个基因有所增加,包括癌症驱动基因,例如 ERBB2、EGFR和CDK6,以及研究较少的基因,例如CLK2、MAP4K5、PPAT、PYGL和SLC12A9。
综合起来,这些分析将过表达的蛋白质优先列为药物再利用或开发的候选基因。
3.由蛋白质过度激活驱动的可靶向依赖性
标题的意思是:癌细胞依赖特定蛋白质的过度激活来生存,我们可以通过设计特定的药物来针对这些蛋白质进行靶向治疗
除了过度表达之外,翻译后修饰还可以改变蛋白质活性,从而驱动肿瘤形成。
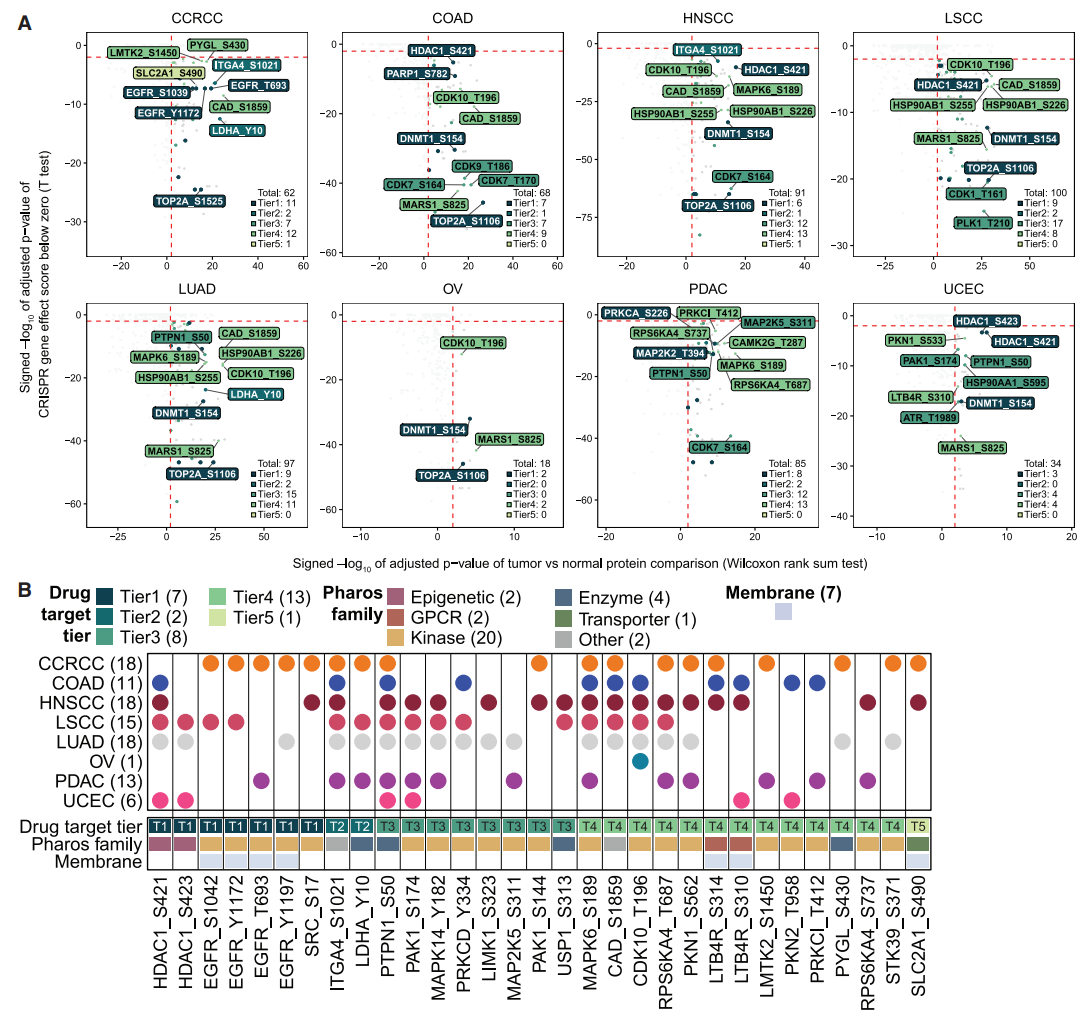
(A)为了确定由蛋白质过度活化驱动的可靶向依赖性,研究对肿瘤和正常样本之间的磷酸位点进行了差异丰度分析,筛选出肿瘤过度表达的可靶向蛋白质上的激活磷酸位点,然后将结果与同一谱系的癌细胞系中其宿主基因的DepMap依赖性评分整合。在8个正常样本队列中,18-100个激活磷酸位点在肿瘤组织中显著增加,细胞系中相应宿主蛋白的基因 敲除后细胞生长相应减少。
(B)这包括总共229个激活磷酸位点-癌症组合,其中90个涉及5个类中的蛋白质磷酸位点。在这些蛋白质过度活化事件中,有31个发生在两种或两种以上的癌症类型中,并且它们的宿主蛋白未被DepMap归类为泛必需。其中20个涉及激酶上的激活位点。八个磷酸位点在五种或更多种癌症类型中共有,包括HDAC1 S421(1类)、ITGA4 S1021(2类)、PTPN1 S50和PAK1 S174(3类)以及MAPK6 S189、CAD S1859、CDK10 T196和RPS6KA4 T687(4类)。一些发现,例如 PTPN1、PAK1 和 CAD,印证了第二部分的蛋白质过表达结果,而其他发现则通过磷酸化位点分析唯一地确定。
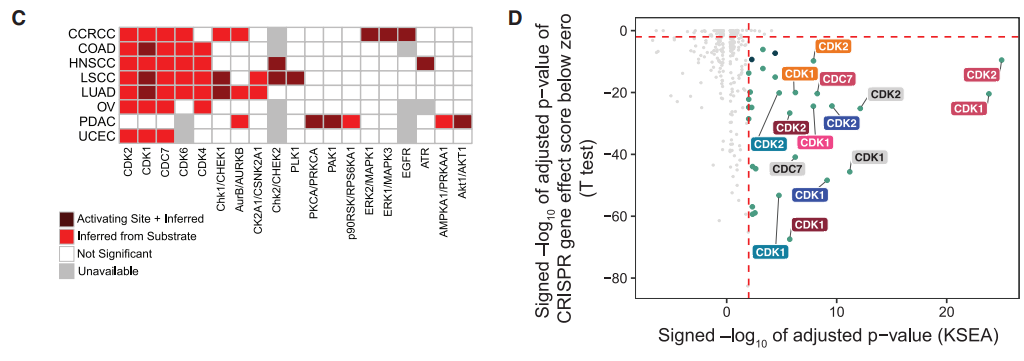
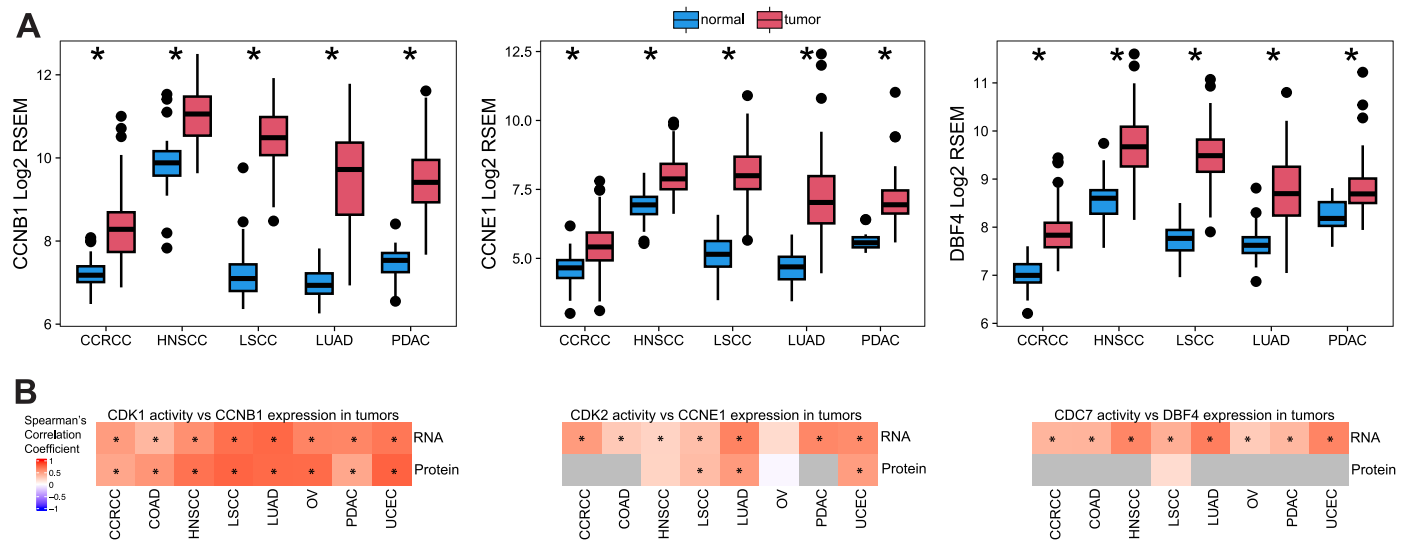
(C)研究使用激酶-底物富集分析(KSEA)算法推断肿瘤和正常样本之间激酶活性的改变。在8个队列中,共有19种激酶活性增加,11种激酶有证据表明在一个或多个队列中激酶活化位点的磷酸化上调。
(D-下AB)在敲除基因数据中,涉及15种独特激酶的31对激酶-癌症对显示肿瘤中的激酶活性增加,并且在相应细胞系中具有显著的依赖性,其中最显著的过度活化激酶是CDK1、CDK2和CDC7。在肿瘤与正常组织中,这些激酶的过度活化由其调节蛋白细胞周期蛋白B1(CCNB1)、细胞周期蛋白E1(CCNE1)和DBF4的过度表达支持。此外,在肿瘤样本中,这些激酶的推断活性与相应调节蛋白的mRNA和蛋白质丰度相关。所有激酶均由肿瘤组织中其底物的过度磷酸化支持,并且一些蛋白质底物也是可药用的,可用于联合治疗。
综合起来,这些分析强调过度活化的蛋白质是潜在有效治疗靶点。
4.预测药物依赖性的评估

(A)为了评估我们预测的质量和有效性,研究首先比较了每个靶标层级中所有假定的可靶向基因中预测有效靶标的比例。预测有效靶标的最高比例始终出现在1类中,因为1类包含已获批准的肿瘤药物的靶标。1类和3类之间的中位比例差异较小。这一发现可能是因为3类基因虽然不是目前获批的肿瘤药物的靶向基因,但通常是肿瘤学研究的重点。
(B)分析相对抑制(PRISM)药物再利用资源的初级筛选数据时发现,在1-3类的1,075种可用药蛋白质中,能够评估648种独特药物对325种具有CPTAC和DepMap CRISPR基因敲除数据的分子靶标的反应。总体而言,这些实验显示所有5,184个药物-细胞谱系对的成功率为 15%。
(C-D)比较了三种不同方法的预测性能:单独使用 CRISPR、单独比较肿瘤与正常细胞以及结合两种策略的方法。整合肿瘤-正常比较和细胞依赖性数据后,识别成功药物反应的最高率,将成功率从 15% 提高到 39%。
(E-G)小提琴图比较了肿瘤与正常和细胞系中对于4类靶标CAD,PAK2和ITGB5的靶蛋白依赖性评分。表明它们是潜在治疗靶点。
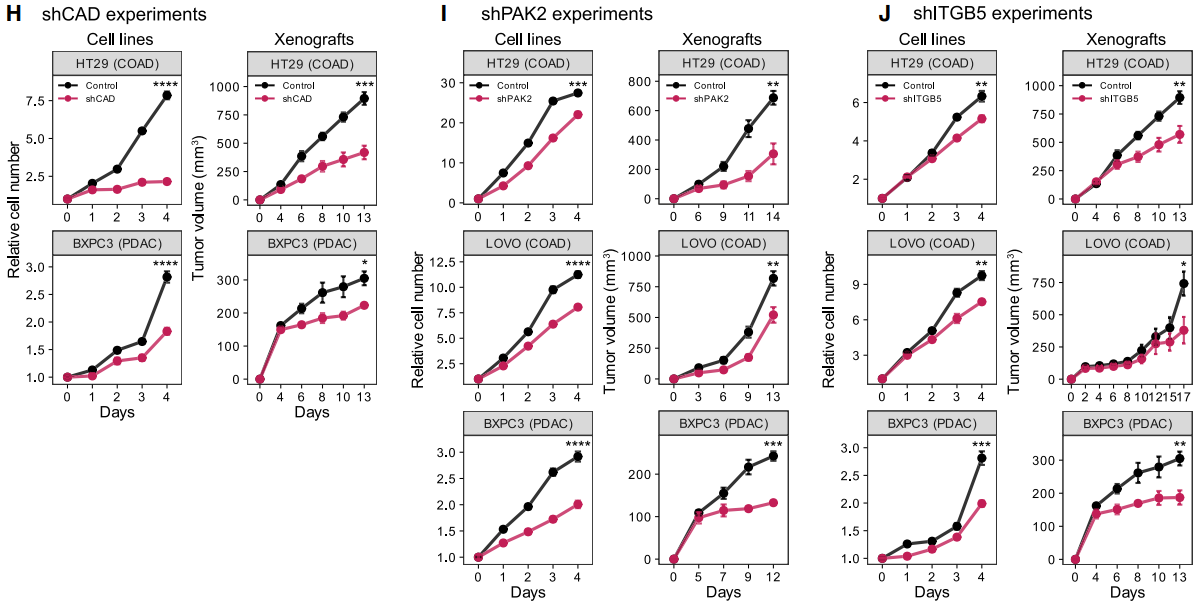
(H-J)针对每个靶标生成了结肠癌(HT29 和 LOVO)和胰腺癌(BXPC3)的稳定shRNA 和对照细胞系。由于技术原因,未生成稳定的shCAD LOVO细胞系。细胞增殖测定表明,与对照组相比,靶标敲低抑制了细胞生长。此外,细胞系异种移植也表明,与对照组相比,这些靶标的敲低抑制了体内肿瘤的生长。
这些结果证明了我们的方法在识别弱点候选目标以及未来药物开发的潜在目标方面的实用性。
5.与TSG缺失相关的蛋白质依赖性
TSG 经常受到癌症中功能丧失 (LoF) 基因组畸变的影响。然而,这些 TSG 的缺失会诱导肿瘤对肿瘤内其他蛋白质的肿瘤特异性依赖性,使这些蛋白质成为合成致死治疗策略的有吸引力的靶点。
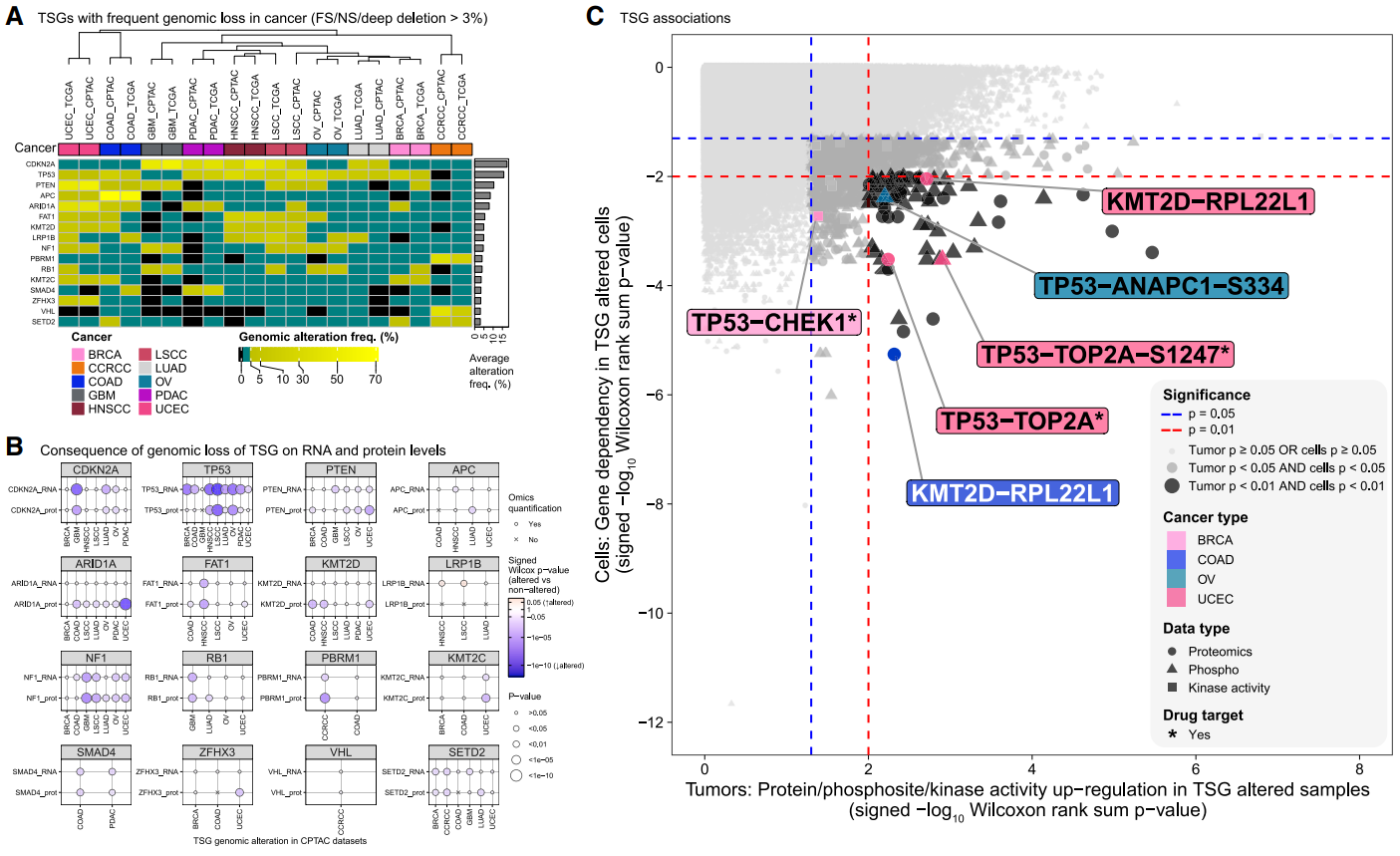
(A-B)我们根据CPTAC和TCGA数据集中发现的TSG中LoF变异的频率对10种癌症类型进行了无监督层次聚类。这些TSG的基因组丢失与同源基因的mRNA和蛋白质丰度降低有关,但与ARID1A和KMT2D的mRNA水平相比,在蛋白质水平上观察到了更大的减少,而TP53则观察到了相反的情况。
(C)为了系统地探索与 TSG 丢失相关的潜在蛋白质依赖性,我们分析了 TSG 的基因组丢失与每种癌症类型的肿瘤样本中蛋白质丰度、磷酸位点丰度和推断的激酶活性评分的变化之间的关联。大多数已识别的 TSG 缺失相关依赖性都是癌症类型特异性的。
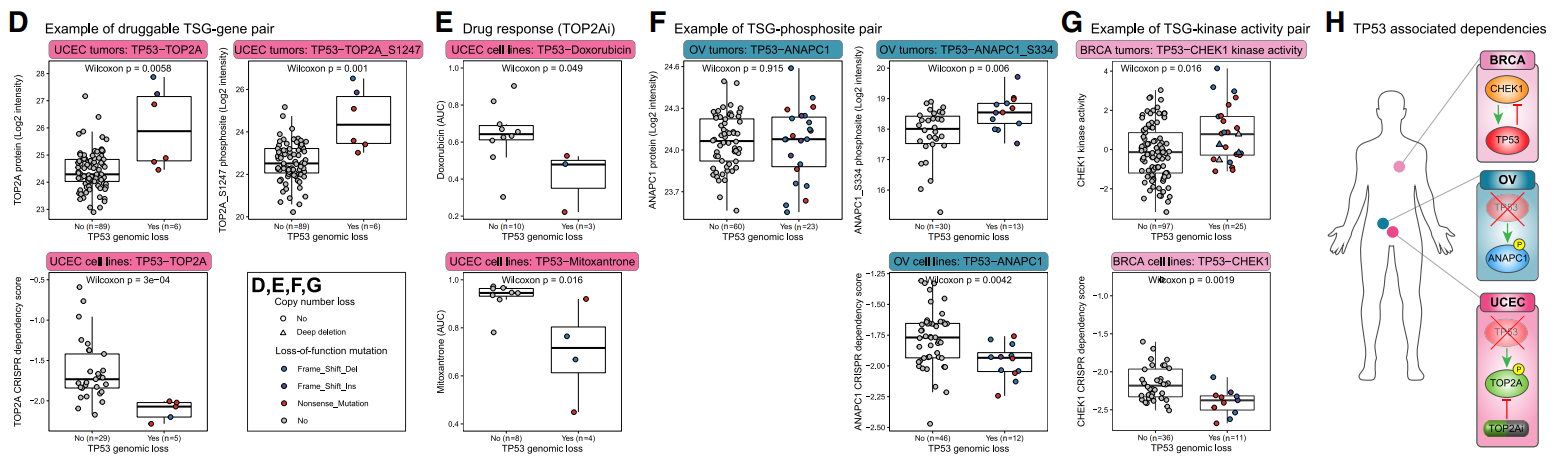
(D)TP53缺失的肿瘤中TOP2A蛋白丰度显著较高,与其他细胞系相比,TP53缺失的子宫癌细胞系对TOP2A的依赖性更高。TOP2A是防止TP53缺失时复制和转录之间相互干扰所必需的。此外,TOP2A S1247水平升高也与TP53缺失有关,这强化了蛋白质水平数据。TOP2A S1247是一个有丝分裂磷酸化位点,会影响酶的亚细胞定位和在有丝分裂染色质上的停留时间,表明TOP2A在含有TP53缺失的肿瘤中具有直接的功能性作用。
(E)TOP2A是化疗药物的靶点。在检查DepMap的体外药物反应数据时,发现与未发生TP53缺失的子宫癌细胞系相比,TP53缺失的子宫癌细胞系对阿霉素更敏感。此外,与野生型(WT)TP53细胞系相比,TP53缺失的子宫癌细胞系对另一种拓扑异构酶抑制剂米托蒽醌的敏感性也增加。据报道,在未经选择的患者中,米托蒽醌对 UCEC 肿瘤缺乏临床活性。这些发现表明,应进一步研究使用TP53缺失作为生物标志物来选择使用阿霉素和米托蒽醌治疗的UCEC患者。
(F)在OV肿瘤中,在含有TP53缺失的样本中,ANAPC1 S334丰度(而非宿主蛋白水平)显着增加。此外,TP53缺失的OV细胞系对ANAPC1的依赖性明显更高。TP53的缺失促进细胞周期进展,这可能会增加对包括ANAPC1在内的后期促进复合物的活性要求。尽管对 ANAPC1 S334 的研究很少,但它可能代表一种研究不足的ANAPC1磷酸盐,可介导ANAPC1活性并最终介导细胞周期进展。
6.新抗原候选物的蛋白质组学鉴定
源自体细胞突变的新抗原是疫苗和基于 T 细胞的免疫疗法的有吸引力的目标。根据人类肿瘤的基因组测序,已预测了数百万种假定的突变衍生的新抗原,但在基于MS的免疫肽组学中检测到的很少。由于新表位是肽而不是核酸序列,并且表达是识别真正新抗原的关键特征,研究推断突变肽的蛋白质组学证据可用于优先考虑体细胞突变以开发免疫疗法。
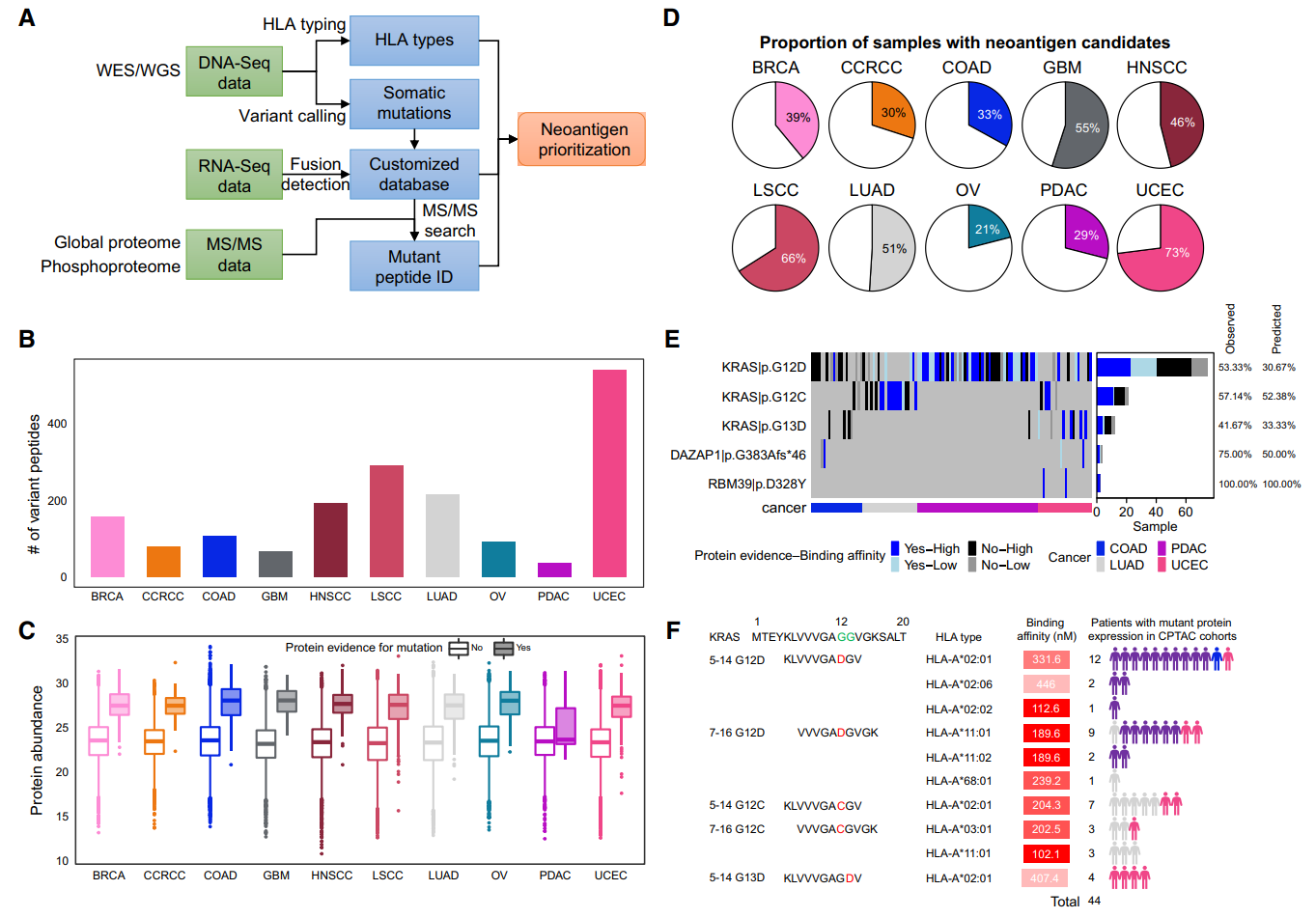
(A-C)使用 NeoFlow 对蛋白质组学、磷酸化蛋白质组学和 DNA/RNA 测序数据进行了综合分析,以预测具有蛋白质表达证据的体细胞突变衍生新抗原。在 10 种癌症类型中,鉴定出 27 至 533 种突变肽。UCEC 中大量突变肽的鉴定是由微卫星不稳定性高 (MSI-H) 或聚合酶 ε (POLE) 突变样本驱动的。与其他癌症相比,LSCC、LUAD 和 HNSCC 中的突变肽数量相对较高,显示了这些癌症的高突变负担。COAD 也有 MSI-H 或 POLE 突变样本。此外,蛋白质水平检测到突变的基因显示出更高的蛋白质丰度,这表明蛋白质丰度在突变肽鉴定中起着重要作用。
(D)研究预测了所有具有蛋白质水平证据的突变表位与患者特异性 HLA 等位基因的结合亲和力。结合亲和力低于 500 nM 的突变表位被视为假定新抗原。在 10 个癌症队列中,具有至少一个预测新抗原的样本比例为 21% 至 73%,表明许多患者可能从基于新抗原的免疫疗法中受益。
(E-F)研究预测的大多数产生新抗原的体细胞突变都是针对单个患者的肿瘤的,产生的新抗原很可能是私有新抗原。然而,预测有五种突变会在至少两种肿瘤中产生新抗原,包括 KRAS G12D、KRAS G12C、KRAS G13D、DAZAP1 G383Afs和RBM39 D328Y。在 75个发生KRAS G12D 突变的肿瘤中,53%产生了可检测到的突变肽,预测31%会产生至少一个KRAS G12D衍生的新表位。预测另外两种KRAS突变也会在大量肿瘤中产生新表位。其中,预测5种KRAS突变肽会在4种CPTAC癌症类型(PDAC、LUAD、UCEC和COAD的44名患者中产生新表位,提示这几种KRAS突变肽是公共新抗原靶向研究对象。
7.肿瘤相关抗原的鉴定和验证
研究预测的大多数突变衍生新抗原都是患者特异性的,这限制了它们作为预制疫苗或 T 细胞产品的靶标的效用。因此,研究进一步通过识别在肿瘤中过度表达而在正常组织中表达受到严格限制的蛋白质,将搜索范围扩大到肿瘤相关抗原(图A)。
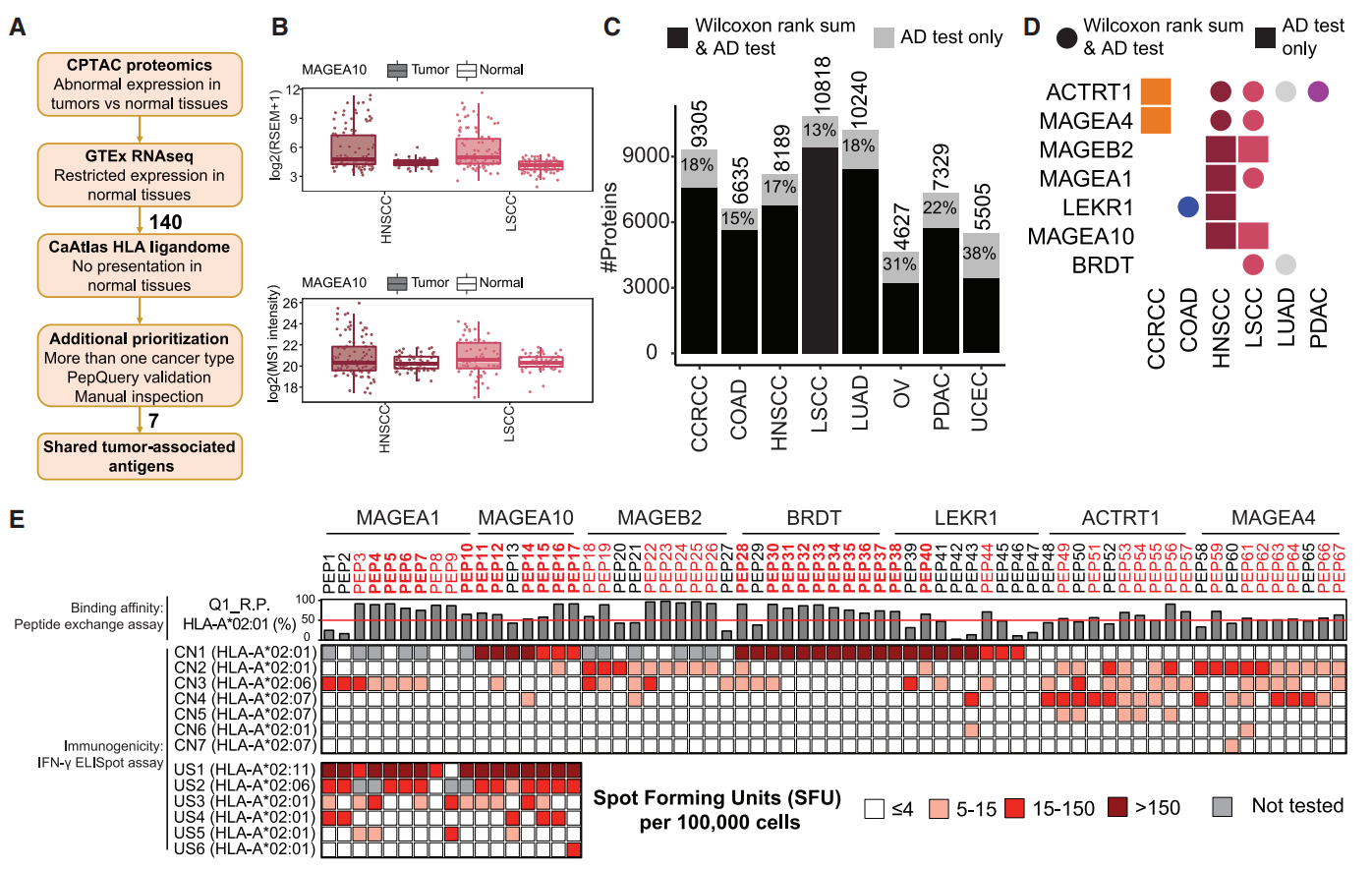
(B)MAGEA10 是黑色素瘤抗原基因(MAGE)家族中高度免疫原性的成员。肿瘤相关抗原在某些癌症类型中仅在少数肿瘤中异常表达。采用 Anderson-Darling (AD) 检验更好地捕捉这些差异。通过过滤 GTEx 项目和 caAtlas 数据库中的正常组织和非癌性样本,使用 PepQuery2 对蛋白质鉴定进行验证。
(C-D)在 8 个正常样本队列中,AD 检验鉴定的显著差异表达蛋白质数量范围为 4,627 至 10,818,增加了 13%–38%。140 种蛋白在 GTEx 正常组织中的表达受到高度限制,包括 5 种 MAGE 家族蛋白。MAGEA10 和 MAGEB2 仅通过 AD 检验鉴定,而 MAGEA4 和 MAGEA1 则在更多癌症类型中通过 AD 检验鉴定。研究了 70 种蛋白的子集,这些蛋白在至少 2 种癌症类型中显著过表达,最终优先考虑 7 种蛋白进行实验验证。
(E)为了开发广泛适用的肿瘤相关抗原用于免疫疗法,选择了与 7 种蛋白质中最常见的 HLA-A 02 型具有最高结合亲和力的 10 种肽。通过竞争性肽结合试验测量了 67 种肽的结合亲和力,其中 70%(47/67 种)肽的交换效率超过了 50%。
总结
-
多组学数据整合:研究团队将蛋白质组学、基因组学、表观基因组学和转录组学数据相结合,直接测量治疗靶点的蛋白质组学数据,并包括磷酸化蛋白质组数据。这种方法揭示了由基因突变、低甲基化和拷贝数扩增驱动的可靶向蛋白质,以及与肿瘤抑制基因丧失相关的蛋白过表达和过度激活,形成潜在的合成致死关系。
-
肿瘤数据和细胞依赖性数据整合:结合肿瘤蛋白基因组数据和癌细胞系的细胞依赖性数据,通过在肿瘤中发现重要蛋白并结合细胞系扰动实验,找到最有可能成功的靶点。
-
跨癌症数据整合:整合多种癌症数据,强化了单一癌症研究中的关联,揭示了多种癌症类型可能共享的治疗靶点,提供了新的跨癌症治疗方向。
-
数据整合计算流程:预测新抗原和肿瘤相关抗原作为免疫治疗的靶点。大多数新抗原特异于个体患者,但有五个KRAS突变肽段在多种癌症类型中产生新抗原。鉴定了140种在正常组织中表达受限但在肿瘤中异常表达的蛋白,其中22个肽段通过实验验证具有强HLA结合亲和力和免疫原性。
-
研究结果平台构建:通过整合10种癌症类型的CPTAC数据和公共数据,研究创建了治疗靶点全景图,并通过在线门户(https://targets.linkedomics.org/)开放,促进药物再利用和新疗法研发,为患者提供更有效的治疗选择。
![Java [ 基础 ] 异常处理 ✨](https://img-blog.csdnimg.cn/direct/d13dd5bb5de3484fa86fe93294d6e112.png)